Flow cytometry¶
You’ll learn how to manage a growing number of flow cytometry datasets as a single queryable collection.
Specifically, you will
read a single
.fcsfile as anAnnDataand seed a versioned collection with it (, current page)
append a new dataset (a new
.fcsfile) to create a new version of the collection ()
query individual files and cell markers (
)
analyze the collection and store results as plots (
)
# !pip install 'lamindb[jupyter,bionty]'
!lamin init --storage ./test-facs --schema bionty
Show code cell output
→ connected lamindb: testuser1/test-facs
import lamindb as ln
import bionty as bt
import readfcs
bt.settings.organism = "human" # globally set organism to human
→ connected lamindb: testuser1/test-facs
ln.context.uid = "OWuTtS4SApon0000"
ln.context.track()
→ notebook imports: bionty==0.49.0 lamindb==0.76.2 pytometry==0.1.5 readfcs==1.1.8 scanpy==1.10.2
→ created Transform('OWuTtS4SApon0000') & created Run('2024-08-30 11:15:56.242932+00:00')
Ingest a first artifact¶
Access  ¶
¶
We start with a flow cytometry file from Alpert et al., Nat. Med. (2019).
Calling the following function downloads the artifact and pre-populates a few relevant registries:
ln.core.datasets.file_fcs_alpert19(populate_registries=True)
PosixPath('Alpert19.fcs')
We use readfcs to read the raw fcs file into memory and create an AnnData object:
adata = readfcs.read("Alpert19.fcs")
adata
AnnData object with n_obs × n_vars = 166537 × 40
var: 'n', 'channel', 'marker', '$PnB', '$PnE', '$PnR'
uns: 'meta'
It has the following features:
adata.var.head(10)
| n | channel | marker | $PnB | $PnE | $PnR | |
|---|---|---|---|---|---|---|
| Time | 1 | Time | 32 | 0,0 | 2097152 | |
| Cell_length | 2 | Cell_length | 32 | 0,0 | 128 | |
| CD57 | 3 | (In113)Dd | CD57 | 32 | 0,0 | 8192 |
| Dead | 4 | (In115)Dd | Dead | 32 | 0,0 | 4096 |
| (Ba138)Dd | 5 | (Ba138)Dd | 32 | 0,0 | 4096 | |
| Bead | 6 | (Ce140)Dd | Bead | 32 | 0,0 | 16384 |
| CD19 | 7 | (Nd142)Dd | CD19 | 32 | 0,0 | 4096 |
| CD4 | 8 | (Nd143)Dd | CD4 | 32 | 0,0 | 4096 |
| CD8 | 9 | (Nd144)Dd | CD8 | 32 | 0,0 | 4096 |
| IgD | 10 | (Nd146)Dd | IgD | 32 | 0,0 | 8192 |
Transform: normalize  ¶
¶
In this use case, we’d like to ingest & store curated data, and hence, we split signal and normalize using the pytometry package.
import pytometry as pm
First, we’ll split the signal from heigh and area metadata:
pm.pp.split_signal(adata, var_key="channel", data_type="cytof")
'area' is not in adata.var['signal_type']. Return all.
adata
AnnData object with n_obs × n_vars = 166537 × 40
var: 'n', 'channel', 'marker', '$PnB', '$PnE', '$PnR', 'signal_type'
uns: 'meta'
Normalize the collection:
pm.tl.normalize_arcsinh(adata, cofactor=150)
Note
If the collection was a flow collection, you’ll also have to compensate the data, if possible. The metadata should contain a compensation matrix, which could then be run by the pytometry compensation function. In the case here, its a cyTOF collection, which doesn’t (really) require compensation.
Validate: cell markers  ¶
¶
First, we validate features in .var using CellMarker:
validated = bt.CellMarker.validate(adata.var.index)
! 13 terms (32.50%) are not validated for name: Time, Cell_length, Dead, (Ba138)Dd, Bead, CD19, CD4, IgD, CD11b, CD14, CCR6, CCR7, PD-1
We see that many features aren’t validated because they’re not standardized.
Hence, let’s standardize feature names & validate again:
adata.var.index = bt.CellMarker.standardize(adata.var.index)
validated = bt.CellMarker.validate(adata.var.index)
! 5 terms (12.50%) are not validated for name: Time, Cell_length, Dead, (Ba138)Dd, Bead
The remaining non-validated features don’t appear to be cell markers but rather metadata features.
Let’s move them into adata.obs:
adata.obs = adata[:, ~validated].to_df()
adata = adata[:, validated].copy()
Now we have a clean panel of 35 validated cell markers:
validated = bt.CellMarker.validate(adata.var.index)
assert all(validated) # all markers are validated
Register: metadata  ¶
¶
Next, let’s register the metadata features we moved to .obs.
For this, we create one feature record for each column in the .obs dataframe:
features = ln.Feature.from_df(adata.obs)
ln.save(features)
We use the Experimental Factor Ontology through Bionty to create a “FACS” label:
bt.ExperimentalFactor.public().search("FACS").head(2) # search the public ontology
| ontology_id | definition | synonyms | parents | molecule | instrument | measurement | __ratio__ | |
|---|---|---|---|---|---|---|---|---|
| name | ||||||||
| fluorescence-activated cell sorting | EFO:0009108 | A Flow Cytometry Assay That Provides A Method ... | FACS|FAC sorting | [] | None | None | None | 100.0 |
| FACS-seq | EFO:0008735 | Fluorescence-Activated Cell Sorting And Deep S... | None | [EFO:0001457] | RNA assay | None | None | 90.0 |
We found one for “FACS”, let’s save it to our in-house registry:
# import the FACS record from the public ontology and save it to the registry
facs = bt.ExperimentalFactor.from_public(ontology_id="EFO:0009108")
facs.save()
! `.from_public()` is deprecated, use `.from_source()`!'
ExperimentalFactor(uid='36GhLFoE', name='fluorescence-activated cell sorting', ontology_id='EFO:0009108', synonyms='FACS|FAC sorting', description='A Flow Cytometry Assay That Provides A Method For Sorting A Heterogeneous Mixture Of Biological Cells Into Two Or More Containers, One Cell At A Time, Based Upon The Specific Light Scattering And Fluorescent Characteristics Of Each Cell.
The Cells Are Suspended In A Stream Of Fluid And Forced Individually Through A Vibrating Nozzle, Then Exposed To A Laser Beam And The Resulting Fluorescence And Scattered Light Is Detected. Finally The Cells Are Sorted By Applying An Electrical Charge To Droplets Of The Fluid And Deflecting It To The Left Or Right Using Charged Electrodes.', created_by_id=1, run_id=1, source_id=62, updated_at='2024-08-30 11:16:03 UTC')
We don’t find one for “CyToF”, however, so, let’s create it without importing from a public ontology but label it as a child of “is_cytometry_assay”:
cytof = bt.ExperimentalFactor(name="CyTOF")
cytof.save()
is_cytometry_assay = bt.ExperimentalFactor(name="is_cytometry_assay")
is_cytometry_assay.save()
cytof.parents.add(is_cytometry_assay)
facs.parents.add(is_cytometry_assay)
is_cytometry_assay.view_parents(with_children=True)

Let us look at the content of the registry:
bt.ExperimentalFactor.df()
| uid | name | ontology_id | abbr | synonyms | description | molecule | instrument | measurement | source_id | run_id | created_by_id | updated_at | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||
| 3 | 21Qymj4Q | is_cytometry_assay | None | None | None | None | None | None | None | NaN | 1 | 1 | 2024-08-30 11:16:03.225845+00:00 |
| 2 | ogoPdeOk | CyTOF | None | None | None | None | None | None | None | NaN | 1 | 1 | 2024-08-30 11:16:03.222821+00:00 |
| 1 | 36GhLFoE | fluorescence-activated cell sorting | EFO:0009108 | None | FACS|FAC sorting | A Flow Cytometry Assay That Provides A Method ... | None | None | None | 62.0 | 1 | 1 | 2024-08-30 11:16:03.208518+00:00 |
Register: save & annotate with metadata ¶
curate = ln.Curate.from_anndata(adata, var_index=bt.CellMarker.name, categoricals={})
curate.validate()
✓ var_index is validated against CellMarker.name
True
curate.add_validated_from_var_index()
artifact = curate.save_artifact(description="Alpert19")
• path content will be copied to default storage upon `save()` with key `None` ('.lamindb/aFXzlz4SBd35a5Xg0000.h5ad')
✓ storing artifact 'aFXzlz4SBd35a5Xg0000' at '/home/runner/work/lamin-usecases/lamin-usecases/docs/test-facs/.lamindb/aFXzlz4SBd35a5Xg0000.h5ad'
• parsing feature names of X stored in slot 'var'
✓ 35 terms (100.00%) are validated for name
✓ linked: FeatureSet(uid='NGadabtWCFN7aovlQbOQ', n=35, dtype='float', registry='bionty.CellMarker', hash='_ia8vfqB8NT5IcKmNhya2w', created_by_id=1, run_id=1)
• parsing feature names of slot 'obs'
✓ 5 terms (100.00%) are validated for name
✓ linked: FeatureSet(uid='NsKavgRmu8jmaFywUm6N', n=5, registry='Feature', hash='SJLJoLtFki5Z515kcmgVlQ', created_by_id=1, run_id=1)
✓ saved 2 feature sets for slots: 'var','obs'
Add more labels:
experimental_factors = bt.ExperimentalFactor.lookup()
organisms = bt.Organism.lookup()
artifact.labels.add(experimental_factors.cytof)
artifact.labels.add(organisms.human)
Inspect the saved artifact¶
Inspect features on a high level:
artifact.features
Feature sets
'var' = 'CD57', 'Cd19', 'Cd4', 'CD8', 'Igd', 'CD85j', 'CD11c', 'CD16', 'CD3', 'CD38', 'CD27', 'CD11B', 'Cd14', 'Ccr6', 'CD94', 'CD86', 'CXCR5', 'CXCR3', 'Ccr7', 'CD45RA'
'obs' = 'Time', 'Cell_length', 'Dead', '(Ba138)Dd', 'Bead'
Inspect low-level features in .var:
artifact.features["var"].df().head()
| uid | name | synonyms | description | gene_symbol | ncbi_gene_id | uniprotkb_id | source_id | organism_id | run_id | created_by_id | updated_at | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||
| 1 | 5R8E1YHbOROI | CD57 | None | B3GAT1 | 27087 | Q9P2W7 | 28 | 1 | 1 | 1 | 2024-08-30 11:15:58.417313+00:00 | |
| 2 | 19Sxm5VN87z8 | Cd19 | None | CD19 | 930 | P15391 | 28 | 1 | 1 | 1 | 2024-08-30 11:15:58.417363+00:00 | |
| 3 | 5CbKd6B4ILaq | Cd4 | None | CD4 | 920 | B4DT49 | 28 | 1 | 1 | 1 | 2024-08-30 11:15:58.417403+00:00 | |
| 4 | 1xRpnOHIkdyE | CD8 | None | CD8A | 925 | P01732 | 28 | 1 | 1 | 1 | 2024-08-30 11:15:58.417484+00:00 | |
| 5 | 7fdKraUfUF8w | Igd | None | None | None | None | 28 | 1 | 1 | 1 | 2024-08-30 11:15:58.417556+00:00 |
Use auto-complete for marker names in the var featureset:
markers = artifact.features["var"].lookup()
markers.cd14
CellMarker(uid='3x83PW1Qiafd', name='Cd14', synonyms='', gene_symbol='CD14', ncbi_gene_id='4695', uniprotkb_id='O43678', created_by_id=1, run_id=1, source_id=28, organism_id=1, updated_at='2024-08-30 11:15:58 UTC')
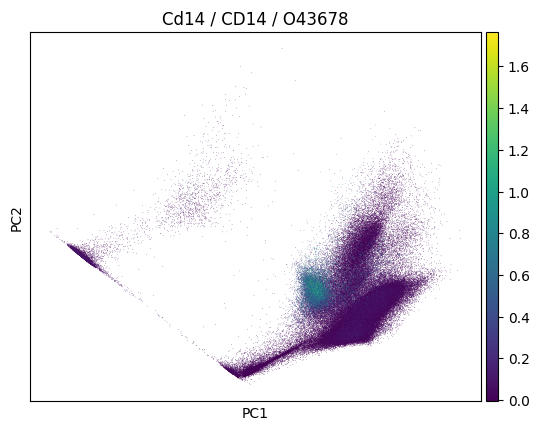
In a plot, we can now easily also show gene symbol and Uniprot ID:
import scanpy as sc
sc.pp.pca(adata)
sc.pl.pca(
adata,
color=markers.cd14.name,
title=(
f"{markers.cd14.name} / {markers.cd14.gene_symbol} /"
f" {markers.cd14.uniprotkb_id}"
),
)
Create a collection from the artifact¶
collection = ln.Collection(
artifact, name="My versioned cytometry collection", version="1"
)
collection
Collection(uid='JiViA1JU17Yq4IVG0000', version='1', is_latest=True, name='My versioned cytometry collection', hash='_SSVHoSL17yyiRlHc8Hrgw', visibility=1, created_by_id=1, transform_id=1, run_id=1)
Let’s inspect the features measured in this collection which were inherited from the artifact:
collection.features
Feature sets
'var' = 'CD57', 'Cd19', 'Cd4', 'CD8', 'Igd', 'CD85j', 'CD11c', 'CD16', 'CD3', 'CD38', 'CD27', 'CD11B', 'Cd14', 'Ccr6', 'CD94', 'CD86', 'CXCR5', 'CXCR3', 'Ccr7', 'CD45RA'
'obs' = 'Time', 'Cell_length', 'Dead', '(Ba138)Dd', 'Bead'
This looks all good, hence, let’s save it:
collection.save()
Collection(uid='JiViA1JU17Yq4IVG0000', version='1', is_latest=True, name='My versioned cytometry collection', hash='_SSVHoSL17yyiRlHc8Hrgw', visibility=1, created_by_id=1, transform_id=1, run_id=1, updated_at='2024-08-30 11:16:04 UTC')